안녕하세요. 오늘 리뷰할 논문은 Few-shot Image Generation with Mixup-based Distance Learning(ECCV2022)이라는 논문입니다. GAN은 기존에 존재하지 않는 이미지를 새롭게 만들기 위해서 고안된 생성모델 중 하나입니다. 그런데 그러한 GAN을 잘 학습시키기 위해선 어느정도의 충분한 양의 데이터를 요구합니다.
GAN이 사용되는 목적 중에 하나는 데이터를 생성하여 보강하기 위함입니다. 즉, 데이터를 확보하는 것이 여유치 않은 경우가 GAN이 필요한 상황 중에 하나라고 볼 수 있습니다. 하지만 잘 작동하는 GAN을 만들기 위해서는 위에서 말했던 것처럼 충분한 양의 데이터를 필요로 하기 때문에 어찌보면 모순적인 상황이 연출됩니다. GAN 분야에서 이러한 문제를 해결하고자 한 것이 Few-shot 계열의 GAN이라고 보시면 되겠습니다.
(https://arxiv.org/abs/2111.11672)
0. Abstract
GAN을 학습하는데 일반적으로 많은 데이터가 필요합니다. 적은 양의 데이터로 GAN을 학습하게 되면 모델이 데이터를 모두 외우는 문제가 생깁니다. 이렇게 되면 "Stairlike" latent space 문제가 발생합니다. 다시 말해 GAN에 이미지 A와 이미지 B의 latent vector a와 b를 가지고 interpolation을 한 vector를 집어넣어도 유의미한 이미지가 나오는 현상이라고 볼 수 있습니다. 이런 경우에는 일반적으로 훈련 때 사용 되었던 latent vector들만 기억해서 해당 vector에 대해서만 그럴 듯 한 이미지를 생성하게 됩니다. 해당 논문에서는 기존 연구와는 다르게 별도의 pretraining이 없이도 few-shot setting에서 GAN을 학습시킬 수 있는 방법론을 제시합니다.
저자들은 데이터가 적은 상황에서 generator와 discriminator의 feature space를 mixup-based distance regularization라는 방법을 통해 학습시킵니다. 이는 모델이 사용된 데이터 포인트 자체를 외우는 방법이 아니라 feature space 내에서의 상대적인 거리를 학습하게 합니다. 덕분에 MixDL은 더욱 제약된 상황에서 feature space interpolation이 smooth하게 잘 되도록 하여 latent continuous한 이미지를 생성합니다.
1. Introduction
Few-shot image synthesis task를 해결하려고한 모델들을 보면 보통 target으로 삼은 데이터셋과 최대한 유사한 source domain dataset을 구해서 이를 활용하는 방법을 취합니다. 해당 논문이 영향을 받았던 Cross Domain Correspondence(CDC)라는 논문도 이와 같은 방법으로 접근을 하는데, 예상할 수 있듯이 source domain dataset과 target dataset(scarse)이 서로 관련이 적어질 수록 사용하기가 어려운 방법입니다.

위 그림은 CDC에서 FFHQ(얼굴데이터셋)에 학습된 source generator를 가지고 target generator를 각각 학습시킨 결과입니다. 10-shot setting이었고, FFHQ와 관련이 높은 Sketch, Animie Face 데이터셋을 target으로 잡고 학습을 할 때는 어느정도 잘 학습이 되는 것을 볼 수 있습니다. 하지만 사람의 얼굴과 전혀 관련이 없는 Flowers, Pokemon, Dog dataset에서 학습된 generator는 좋지 않은 이미지를 생성하는 것을 확인할 수 있습니다. 이를 통해 source generator를 활용하는 방법의 한계를 확인할 수 있습니다. CDC의 학습 방법은 아래에 간단하게 나오니 참고하시면 좋을 것 같습니다.
데이터셋에 존재하지 않으면서도 양질의 이미지를 생성하는 few-shot GAN을 만들기 위해서 저자들은 직접적으로 "image quality problem"과 "near-perfect memorization" 문제를 해결하려고 하기 보단 간접적인 문제 정의/접근으로 문제를 해결하려하였습니다.
위에서 언급했던 것처럼 stairlike latent space problem을 해결하는 것을 목표로 잡고 접근했다고 보시면 되겠습니다. 다시 한 번 말해보자면 stairlike latent problem은 학습할 수 있는 데이터가 너무 적은 상황에서 발생하는 문제입니다. 학습에 사용할 수 있는 샘플 수가 적어지다보니 모델이 latent space를 굉장히 띄엄띄엄, 특정 지점만 학습을 하게 됩니다. (반대로 데이터가 풍부한 경우에는 latent space 상에서 촘촘하게 다양한 latent vector가 사용되게 되고, 이 덕분에 latent가 high-level sementic도 담을 수 있으면서 유의미한 latent interpolation도 가능하게 됩니다.) 그 결과 학습 데이터가 적은 경우 학습에 사용된 latent vector point만 유의미한 vector가 되고, 이 외의 vector 값들은 유의미한 이미지를 만들어 내지 못하게 됩니다. (Latent space가 계단처럼 뚝뚝 끊긴다 해서 stairlike latent problem이라고 부르는 듯 합니다. )

위 이미지의 왼쪽을 보면 MixDL을 제외한 모델을 보면 학습 데이터를 아예 외우거나, collapse가 일어난 것을 볼 수 있습니다. 그리고 오른 쪽을 보면 MixDL이 가장 왼쪽 이미지와 가장 오른쪽 이미지의 latent을 interpolation 해가면서 이미지 생성을 했을 때 가장 자연스러운 것을 볼 수 있습니다.
해당 논문의 Contribution은 아래와 같습니다.
- Latent space가 smooth하고 mode를 잘 유지할 수 있는 two-sided distance regularization 방법을 제안하였다.
- 많은 양의 source domain dataset 없이도 이미지를 잘 생성할 수 있는 간단한 few-shot image generation framework를 제안하였다.
- 다양한 데이터셋에서 MixDL을 실험하여 다방면으로 효과적인 방법임을 보였다.
2. Related Works
One-shot image generation / Low-shot image generation / Few-shot image generation with auxiliary dataset / Generative dicersity / Latent mixup에 대해서 다루고 있습니다. 해당 주제가 궁금하신 분은 논문을 참고하시면 좋을 듯 합니다.
3. Approach
위에서 언급했던 것처럼 overfitting 문제를 직접적으로 해결하지 않고, 이의 부산물 같은 stairlike latent problem을 해결하면서 few-shot GAN 학습을 하려고 시도합니다. 저자들은 mixup-based distance learning(MixDL)을 제안하였습니다. 이를 통해 G/D가 latent space를 부드럽게 학습할 수 있게 하였고, 덕분에 다양한 샘플을 생성할 수 있었습니다.
저자들이 제시하는 framework는 아래와 같으며 아래 설명을 읽다보시면 차차 이해가 가실 것 입니다.

3.1. Cross-Domain Correspondence(CDC)
해당 논문의 방법론은 CDC의 방법에서 착안한 방법이기에 방법론의 설명을 CDC에 대한 소개로 시작하고 있습니다. CDC는 앞서 말씀드린 것처럼 source generator의 미리 학습된 지식을 target generator에 주입하는 방식입니다. CDC는 아래와 같은 방식으로 학습을 진행합니다. \(z_{i}\)는 latent vector를 나타내고, \(G_{s}^{l}\)은 source generator의 l번째의 activation layer를 의미합니다. \(G_{s->t}^{l}\) 는 target generator를 나타냅니다. 아래 식처럼 latent vector간의 유사도를 가지고 softmax 취하여 \(p^{l}\)과 \(q^{l}\) 을 구합니다. \(z\)는 prior distribution에서 임의로 정해집니다.

그리고 \(p^{l}\)과 \(q^{l}\)를 KL divergence term을 가지고 최대한 비슷한 분포가 되게끔 loss를 흘려줍니다. 이렇게 하면서 target generator가 source generator와 어느정도 비슷하게 동작할 수 있도록 학습을 하게 됩니다.

3.2. Generator Latent Mixup
해당 논문에서는 source generator를 사용하지 않기 때문에 위와 같은 접근과는 다른 방식을 사용합니다. Mode를 유지하면서 interpolation이 가능한 latent space를 만들기 위해서 anchor point라고 불리는 \(z_{0}\)는 사용할 수 있는 sample들을 Dirichlet 분포를 사용해서 잘 섞어주어서 만들었습니다.

그리하여 \(z_{0}\)는 위 framework figure에서 나온 것처럼 실제 소수의 학습 이미지의 latent의 중간 어딘가에 놓이게 됩니다.

\(q_{l}\)은 \(z_{0}\)과 \(z_{i}\)를 입력으로 넣은 결과 값의 유사도(거리)를 가지고 계산되게 됩니다. \(z_{0}\)가 만들어진 과정을 생각해보면 \(z_{0}\)와 나머지 latent vector들 간의 거리는 \(c_{1~N}\)에 비례한다고 생각할 수 있습니다. 그리하여 p와 비슷한 분포가 나오도록 학습이 된다면 latent들이 distribution distance aware하게 학습이 되게 될 것 입니다.
3.3. Discriminator Feature Space Alignment
Discriminator도 위와 비슷한 방식으로 학습을 진행합니다. \(d_{(1)}\)은 discriminator의 마지막 FC layer 직전까지를 나타냅니다. \(d_{(1)}\)에 SSL분야에서 많이 사용하는 것처럼 projection layer를 달아서 discriminator에서도 p의 분포를 따라가게끔 학습을 진행합니다.
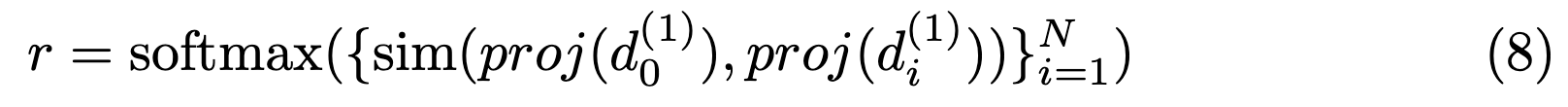

3.4. Final Objective
최종적으로는 adversarial loss에 위의 loss term을 추가하여 사용합니다.

4. Experiments
MixDL은 unconditional GAN 쪽에서 SOTA 모델인 StyleGAN2를 위에서 적용되었습니다.
4.1. Qualitative Result

위 이미지는 MixDL을 다른 모델과 비교한 것입니다. 10-shot image generation task를 진행했을 때 비교 대상이 된 모델의 경우 collapse가 일어나거나 training data를 아예 외워버리는 모습을 보였습니다.
4.2. Quantitative Evaluation

마찬가지로 10-shot image generation task를 가지고 학습을 한 결과 위와 같은 결과가 나왔습니다. 가장 성능이 좋은 모델은 볼드체로, 두번 째로 성능이 좋은 모델을 밑줄로 표시되어 있습니다. 앞에서 나왔던 것처럼 CDC는 pretrained generator를 사용하기에 완전히 동일한 상황에서의 비교라고 보긴 힘들지만 위의 표를 통해서 CDC는 pretrained dataset인 FFHQ와 멀어질 수록 점점 성능 저하가 일어남을 확인할 수 있습니다.

이 외에도 다른 실험 결과들입니다.
4.3. Ablation Study

왼쪽 표는 Generator와 Discriminator에 MixDL을 넣고 빼가면서 실험을 진행한 것입니다. 오른 쪽 표는 MixDL에서 사용하는 distribution의 종류를 바꿔가면서 실험을 한 것입니다.

빨간 선은 FFHQ-babies, 파란 선은 flowers로 모델을 학습한 것입니다. 학습에 사용된 데이터를 점점 늘려가면서 성능을 비교한 것입니다. Few-shot setting일 때 MixDL을 사용하는 것이 도움이 되는 것을 확인할 수 있습니다.
4.4. Latent Space Smoothness

이미지의 latent를 가지고 interpolation하면서 이미지를 생성했을 때 이미지가 smooth 하게 바뀌는 모습을 확인할 수 있습니다. 다른 모델의 경우 latent를 interpolation 하면서 이미지를 생성하지만 stairlike 하게 이미지가 휙휙 바뀌거나 제대로 생성되지 않는 양상을 보입니다.