안녕하세요. 오늘 리뷰해볼 논문은 BEiT: BERT Pre-Training of Image Transformers입니다.
과거에 BERT의 pretrain 방법 중 하나였던 masked language modeling(MLM)은 방대한 학습량을 필요로 하는 transformer 계열 모델에 효과적인 방법으로 알려져있습니다. Vision 분야에서도 추가적인 labeling 작업 없이 샘플 중간에 masking을 하고 그것을 유추하는 유사한 pre-train 방법이 시도되었습니다. BEiT도 이러한 접근법을 사용한 Vision 분야의 Transformer 계열 모델입니다. 일전에 리뷰했던 MAE 논문도 MLM에 영향을 받아서 제안된 논문인데, 두 논문이 발표된 시기를 보면 어느정도 concurrent한 연구였던 것 같습니다.
(해당 글은 개인적인 기록을 목적으로 잘못된 내용이 있을 수 있음을 알립니다.)
(https://arxiv.org/abs/2106.08254)
MAE 논문 리뷰: https://dhk1349.tistory.com/5
[논문 리뷰] Masked Autoencoders Are Scalable Vision Learners
오늘 리뷰할 논문은 Facebook AI Research(FAIR)에서 Kaiming He의 주도로 발표된 Masked Autoencoders Are Scaleable Vision Learners입니다. 해당 논문에서 제안한 MAE(Masked Autoencoder)는 기존의 다른 Transformer 기반의 vision
dhk1349.tistory.com
0. Abstract
본 논문에서는 visual representation을 자기지도학습(self-supervised learning) 방식으로 학습할 수 있는 BEiT(Bidirectional Encoder representation from Image Transformers)를 제안합니다. 저자들은 BERT의 MLM pre-train task를 vision 분야로 가져온 MIM(masked image modeling)를 제안합니다. BEiT에서는 이미지 데이터를 크게 두 가지 방식으로 다룹니다. 첫 번째가 image patch, 두 번째가 이산적인 visual token입니다.
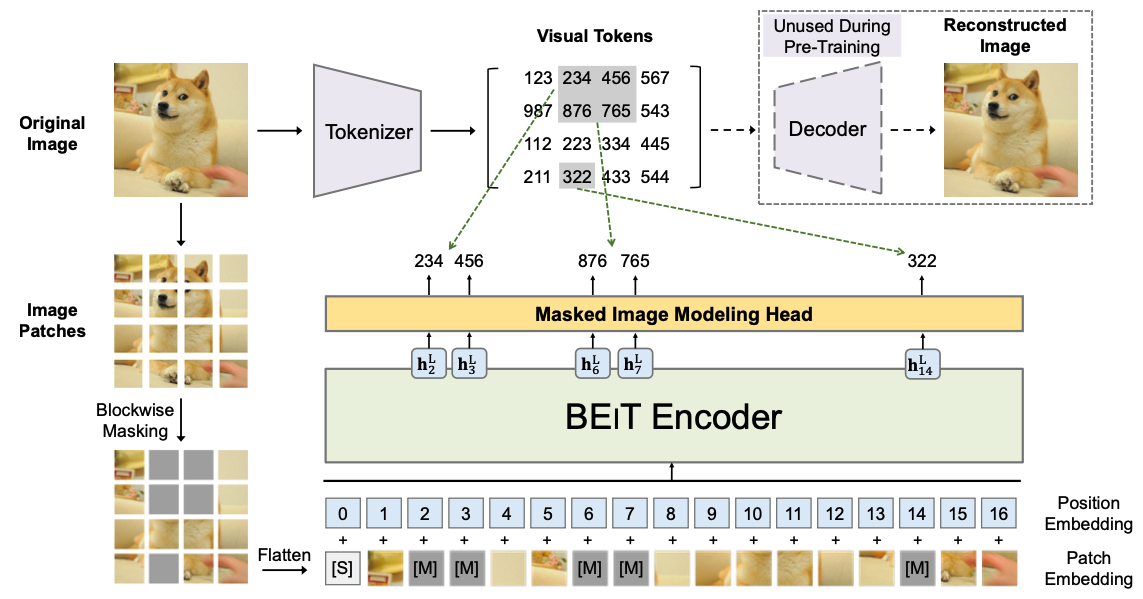
Pre-train 방식을 먼저 아래 그림과 함께 소개해보겠습니다. 일단 BEiT로 들어가는 입력 부분은 여느 다른 Transformer 기반 visual encoder와 같다고 보시면 됩니다. 이미지를 겹치지 않는 여러 개의 patch들로 나눕니다. 그리고 이 중 임의로 정해진 비율 만큼의 patch들을 masking 해줍니다. 그리고 이를 일자로 펴서 positional embedding을 더해줍니다. 이미지 patch를 NLP의 하나의 token과 대응되는 개념입니다. MAE는 masking된 부분이 encoder로 들어가지 않았지만 여기서는 masked 된 채로 patch가 들어가게 됩니다. 이 부분 때문에 encoder의 연산효율은 MAE가 더 좋긴 합니다.
그리고 MLM과 동일하게 MLP head를 통해서 masking이 된 자리의 값이 원래 무엇이었는지를 맞추도록 학습합니다. 여기서 문제가 Language Model의 입력 값은 discrete token이기 때문에 MLP head에서 마치 class classification하는 것처럼 어떤 token이었는지를 맞춰주면 됩니다. 하지만 Vision Encoder들을 보면 입력으로 들어오는 token(patch라고 불러왔던 것)은 픽셀 값들로, discrete하지 않고 continuous한 정보입니다. 그렇기 때문에 아무리 입력 patch를 하나의 token이라고 여겨도 MLP head 같이 작은 네트워크로 masking 되었던 patch의 픽셀 하나하나를 유추해내는 것은 불가능에 가깝습니다.
그렇기 때문에 MAE 같은 경우에는 별도에 Decoder를 가지고 비어있던 patch를 복원한 것이라고 봅니다.
BEiT 같은 경우에는 continuous한 patch 정보를 discrete한 token으로 만들어주기 위해서 VQVAE를 사용합니다. 간단하게 말하자면 patch 하나를 234, 456 같은 이산적인 visual token 하나로 대응되도록 VAE를 학습하고 이를 활용하는 방법입니다. BEiT에서는 픽셀 기반 patch를 복원하는 대신에 MLP head를 가지고 discrete visual token(234, 456 같은)을 맞추도록 구조를 구상하였습니다.
위와 같은 MIM 방식으로 BEiT를 pre-train한 뒤에 Head 같은 것을 붙여서 다양한 downstream task에 맞게 학습을 했다고 합니다. 여기서 중요한 것들은 많이 커버하고 넘어간 듯 합니다.
1. Introduction
Transformer 계열의 모델을이 computer vision 분야에서 성공을 거두었고, 다양한 self-supervised learning 방식으로 인해서 학습 시 데이터가 많이 필요한 transformer 계열 모델들의 이슈들이 어느정도 해결되었습니다.
하지만 이와 동시에 NLP 쪽에서 성공적인 성과를 냈던 MLM을 Vision 계열의 transformer에 적용하는데 여러 문제가 있었다고 합니다. 위에서 언급했던 것과 겹치는 부분인데 NLP에서의 token은 discrete하지만 vision의 token은 그렇지 않다는 것. 그렇기에 vision 계열에서는 masking된 pixel token들을 regression하듯이 계산을 해야하고 이를 통해 계산의 부담이 커진다는 것이 문제라고 볼 수 있습니다. 해당 논문에서는 이 문제를 discrete visual token을 만들면서 해결하려고 하였습니다. BEiT의 backbone(encoder)는 ViT와 동일한 transformer encoder를 사용하였습니다.
해당 논문에서 주장하는 contribution은 다음과 같습니다.
- 자기지도학습 방법론인 MIM task로 vision transformer를 pre-train하는 방법을 제안하였습니다.
- BEiT를 pre-train하고 다양한 downstream task에 fine-tuning을 진행하였습니다.
- Human-guided data 없이 self-attention mechanism만 가지고 이미지나 객체를 인지할 수 있다는 것을 보였습니다.
2. Method
2.1. Image Representations
Image Representation을 두가지 방식으로 바라보고 사용합니다. (image patch, visual tokens)
2.1.1. Image Patch
ViT와 동일한 방식이라고 봐도 무방합니다. 해당 논문 리뷰를 보고 계시다면 image를 어떻게 patchify하는지 잘 알고 계실 듯 합니다. 이미지를 겹치지 않는 여러 개의 격자로 나눈 뒤 이를 일 자로 펴서 사용합니다. 여기에서는 224x224 이미지를 14x14 픽셀의 이미지 patch로 나누어서 총 16x16개의 patch를 만들어 사용합니다.
2.1.2. Visual Token
이미지 patch를 discrete한 token으로 만들기 위해서 dVAE(VQVAE)를 사용합니다. VQVAE는 encoder(tokenizer), codebook(visual tokens), docoder로 구성이 되어있습니다. VQVAE의 encoder와 decoder의 역학은 VAE와 크게 다르지 않습니다. Encoder는 들어오는 patch 입력에서 핵심적인 feature를 뽑아내서 압축합니다. Decoder는 핵심적인 feature를 가지고 최대한 손실 없이 원본에 가깝에 만드는 역학을 합니다.
그리고 VQVAE를 VAE와 다르게 만드는게 codebook이라고 보시면 될 것 같습니다. 아래 그림은 VQVAE의 구조입니다. Codebook(아래에서는 Embedding space라고 표기)은 k개의 서로 다른 dim 차원의 vector로 되어있습니다. encoder의 결과 값과 차원이 같습니다. 그리고 k개의 embedding vector들은 바뀌지 않고 discrete한 token의 역할을 합니다. 해당 논문의 visual token과 같습니다. 그리고 학습을 하는 과정에서 encoder가 자연스럽게 embedding vector중에 하나로 mapping이 되도록 학습을 진행합니다. 자세한 내용은 해당 논문에서 찾아보실 수 있습니다.

2.2. Backbone Network: Image Transformer
ViT backbone을 사용했다고 합니다.
2.3. Pre-Training BEiT: Masked Image Modeling
해당 논문에서는 masked image modeling(MIM) task를 제안합니다. 40%정도의 patch들을 masking했다고 합니다. 단, 완전 임의로 40%를 masking하지 않고 image patch를 뭉쳐서 block 단위로 masking을 했다고 합니다.

2.4~
Image Classification, Semantic segmentation, Intermediate fine-tuning에 대해서 fine-tuning을 진행했습니다.
Adam optimizer를 사용했으며 500k step 동안 학습했습니다. ViT와 비교를 하기 위해서 ViT와 동일한 configuration을 사용했다고 합니다. 추가적인 내용은 논문을 확인해보시면 좋을 것 같습니다.
3. Experiments
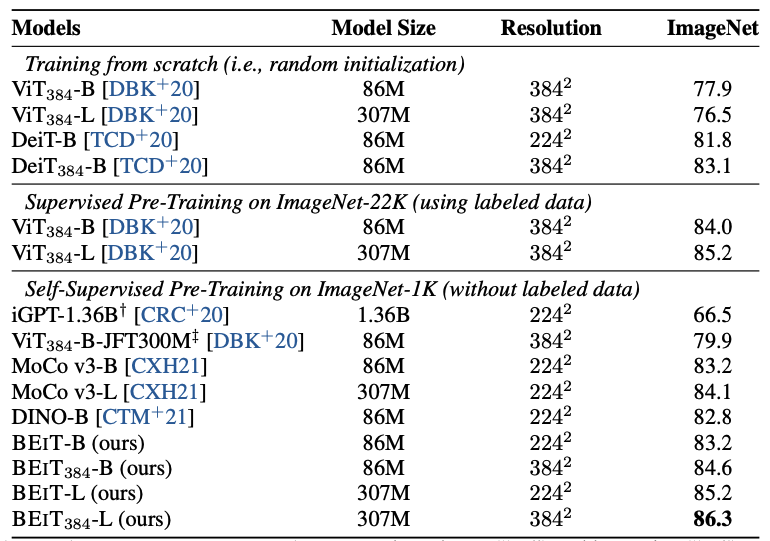
일단 BEiT가 가장 높은 성능을 보이고 있습니다. 그리고 encoder의 구조가 일치하는 ViT와 비교를 했을 때, 성능이 비슷해보이겠지만 ViT는 학습에 사용된 labeled data가 압도적으로 많다는 점과 BEiT는 훨씬 적은 unlabeled data를 사용했다는 차이가 있습니다. 이를 통해서 훨씬 더 제약된 상황에서도 학습 방법에 따라 비슷하거나 우수한 성능을 보이는 것을 확인할 수 있습니다.

논문에서 소개 된 여러 가지 요소들을 가지고 ablation을 진행 한 결과 위 표와 같은 양상을 보입니다.
4. Related Work
SSL과 관련된 내용을 다루고 있습니다. 여기서부터 궁금하신 부분은 논문을 읽어보시는 것을 추천드립니다.
5. Conclusion
Vision Transformer를 효과적으로 pre-train하기 위한 self-supervised learning 방법론을 제시하였습니다.