안녕하세요. 오늘 리뷰할 논문은 MoCo라고 불리는 Momentum Contrast for Unsupervised Visual Representation Learning라는 논문입니다. Facebook에서 2020년에 발표했고, self-supervised 방식으로 visual encoder를 학습시키는 방법을 소개하고 있습니다. 비슷한 류의 논문인 MoCo v2, MoCo v3, SimCLR, BYOL 같은 논문들도 차례로 리뷰해보도록 하겠습니다.
(https://arxiv.org/pdf/1911.05722.pdf)
Self-supervised learning은 이미지의 라벨 없이도 이미지만 가지고 학습을 할 수 있습니다. 그렇기 때문에 대량의 이미지를 가지고도 모델 학습이 가능합니다. 대량의 이미지를 self-supervised 방식으로 학습하게 되면 이미지 라벨에 구애받지 않고 이미지의 유효한 representation을 뽑아내는 encoder를 학습할 수 있게 됩니다. 그리고 해당 encoder를 downstream task에 맞에 fine tuning을 하는 등의 방식으로 사용하 수도 있습니다.
MoCo의 학습 방식은 여기서 나온 encoder를 사용할 때 뿐만 아니라 개인 연구를 진행하는 과정에서 self-supervised learning method로 모델 학습을 진행하는 경우 방법론 자체를 차용할 수 있기 때문에 알아두면 좋을 듯 합니다.
0. Abstract
해당 논문의 저자들은 Momentum Contrast(MoCo)를 제안합니다. MoCo는 다른 방법들처럼 contrastive learning 관점으로 dictionary를 사용합니다. Queue와 moving-averaged encoder를 사용해서 거대하고 일관성있는 dictionary를 만들수 있게 합니다. 이 덕분에 encoder가 좋은 representation을 학습할 수 있었습니다. 여기서 나오는 dictionary란 이미지들을 encoder에 통과시켜서 얻은 representation들의 모음이라고 생각하면 됩니다. MoCo는 ImageNet classification의 linear protocol 상에서 준수한 결과를 얻었으며, 다양한 downstream task에서 supervised pre-training 모델들을 제치고 우수한 성능을 보였다고 합니다. 자세한 방법은 뒷 부분에서 설명해보도록 하겠습니다.
1. Introduction
Language 분야는 BERT와 GPT를 시작으로 un/self-supervised 방식들이 성공적인 모습을 모였습니다. 하지만 (당시 기준으로) un/self-supervised 방식은 supervised learning과 비교했을 때 성능 상으로 밀리는 모습을 보여줍니다. 이는 저자들에 따르면 language와 vision의 구조적인 차이라고 유추해볼 수 있습니다. Language는 데이터가 discrete한 성질인 단어로 이루어져있습니다. 그렇기 때문에 dictionary와 representation space도 discrete한 성질을 띄고 있습니다. 반면 vision의 이미지 데이터는 픽셀로 이루어져있기 때문에 데이터가 raw/continuous/high-dimensional 하다는 특징을 띕니다.
일단 더 자세한 소개를 하기에 앞서서 이미 말했 듯이 dictionary는 representation의 집합입니다. 그리고 dictionary를 구성하는 각 representation을 key라고 부릅니다. 그리고 key(representation)를 뽑아내는 encoder에는 이미지가 들어갈 수도 있고 이미지의 일부인 패치가 들어갈 수도 있습니다. 그리고 추후에 사용을 목적으로 하는 encoder에서 뽑아내는 representation은 query라고 부릅니다.

Query와 dictionary의 key들을 가지고 contrastive loss를 줄 때 query와 같은 쌍을 이루는 key에 대해서는 가까이, 나머지 key에 대해서는 멀어지도록 학습을 합니다. 여기서 효과적으로 학습을 하기 위해서는 dictionary가 클 수록 좋으며 dictionary를 구성하는 key의 representation이 일관적인 것이 좋습니다. Dictionary의 크기가 커지면 encoder가 멀리해야할 negative sample들을 한꺼번에 많이 보고 학습할 수 있기 때문에 유리한 것입니다. 그리고 일관성 부분에 대해서는 만약 위 그림에서 key(representation)을 뽑아내는 encoder가 contrastive loss를 통해서 iteration마다 weigth가 갱신된다고 가정해봅시다. 그렇게 되면 key를 뽑아내는 encoder의 weight가 (비교적) 확확 바뀌게 되고, 그에 따라 key representation이 계산되는 방식(모양)도 크게 바뀌게 됩니다. Dictionary(queue) 안에는 여러 개의 mini-batch를 쌓아서 크기를 최대한 키우게 되는데 key(representation)가 뽑히는 모양새가 계속 바뀌면서 dictionary를 구성하게 되면 key들의 일관성이 적어지고 query encoder 학습을 방해하는 요소가 됩니다.
MoCo의 저자들은 "a slowly progressing key encoder" 즉 key encoder를 점진적으로 천천히 업데이트 하면서 dictionary의 일관성을 유지하면서 크기를 키우는 방법을 제안합니다. key encoder에는 contrastive loss를 흘려주는 대신 query encoder의 weight를 momentum-based moving average 방식으로 key encoder에 흘려주는 방식으로 key encoder를 천천히 학습시키는 방법을 선택합니다. 결과적으로는 abstract에서 말했던 것처럼 다양한 task에서 supervised 모델을 포함해서 비교해도 우수한 성능으로 보였습니다.
2. Related Work
다양한 loss function, pretext task에 대한 내용이 있습니다. 궁금하신 분은 논문을 찾아보시면 좋을 것 같습니다.
3. Method
3.1. Contrastive Learning as Dictionary Look-up
위 제목에서 나온 것처럼 저자들은 MoCo가 사용하는 contrastive loss를 사전을 찾아보는(dictionary loo-up) 것으로 비유합니다. 그렇게 하는 이유는 여러 mini-batch들이 합쳐서 만들어진 거대한 dictionary 안에서 query와 같은 쌍인 positive key를 가장 유사도가 높게하는(사전에서 찾아내는) 것이 목적이기 때문입니다.

Contrastive loss는 이 글을 읽는 분이라면 친숙하신 분이 더 많겠지만 위의 식입니다. q는 query 즉 query encoder에서 뽑아낸 이미지 representation이고 k는 key로, key encoder에서 뽑아낸 representation입니다. k+는 q와 같은 쌍의 이미지라는 의미입니다. 그래서 위 식은 positive pair의 유사도(q*k+)는 높게, 나머지 negative pair들과는 낮게 만드는 것이 목적이라고 보면됩니다. 쉽게보면 k+1개의 후보지를 가지고 softmax를 하는 것과도 크게 다르지 않다고 저자들은 표현합니다.
그리고 query encoder와 key encoder는 아예 같은 구조를 사용하기도 하고, 구조의 일부만 공유하기도 하고, 아예 다르기도 하다고 합니다. 물론 여기서는 query encoder의 weight를 key encoder에 흘려줘야하니 같은 구조를 사용할 것 입니다.
3.2. Momentum Contrast
Dictionary as a queue
Moco에서는 key encoder를 천천히 업데이트 하면서 dictionary의 일관성을 유지하였습니다. 이 때 여러 개의 mini-batch를 누적해서 dictionary를 만든다고 하였습니다. 그런데 이 mini-batch를 무한정 쌓아두진 않고 queue 형태로 queue가 꽉 찼다는 가정 하에 가장 들어온지 오래된 mini-batch를 dequeue하고 새로운 mini-batch를 enqueue한다고 합니다. 이는 dictionary 사이즈를 무한정으로 키울 수는 없기 때문에 당연한 것이긴 한데, 또 다른 측면에서 보자면 key encoder가 아무리 천천히 바뀐다고 해도 바뀌긴 바뀌니까 쌓인지 오래된 mini-batch와는 consistency가 유지되지 힘들기 때문도 있습니다.
Momentum update
key encoder의 weight는 아래와 같은 방식으로 업데이트 합니다. key encoder의 weight와 query encoder의 weight를 m:(1-m) 비율로 섞어서 key encoder의 weight를 업데이트 하는 것 입니다. 이 때, m을 0.9~0.999 정도로 설정합니다. 1-m의 크기가 매우 작기 때문에 key encoder가 천천히 momentum을 가지고 바뀌는 것입니다.

Relations to previous mechanism
MoCo를 다른 방법들과 비교하였습니다. (a) 같은 경우는 contrastive를 양쪽 encoder에 모두 흘려서 학습을 시킵니다. 이러면 encoder k가 지속적으로 크게 바뀌기 때문에 dictionary size를 mini-batch만큼으로 할 수 밖에 없습니다.
두 번 째는 memory bank를 사용하는 방식입니다. Memory bank의 sample은 epoch를 돌아서 새롭게 forward가 됐을 때 업데이트된다고 합니다. 이렇게 되면 마찬가지로 memory bank 내부 원소들의 업데이트 주기가 굉장히 길어져서 representation의 일관성을 유지하기가 힘들어집니다.
마지막 방식이 몇 개의 mini-batch를 쌓아두는 momentum encoder를 사용한 MoCo입니다.

3.3. Pretext Task
저는 pretext task를 모델을 pretrain 하는 objective 정도로 해석했습니다. MoCo에서는 새로운 pretext task를 제안하는게 목적이 아니기 때문에 기존에 존재하는 pretext task를 최대한 그대로 사용했다고 합니다. 아래는 MoCo의 pseudo code인데
크게 어렵지 않고 실제 코드도 엄청 복잡한 편은 아니니 직접 코드를 보셔도 도움이 될 것 같습니다. (https://github.com/facebookresearch/moco)

Technical details
해당 내용은 궁금하시면 논문을 찾아보시면 좋을 것 같습니다.
Shuffling BN(batch normalization)
그냥 BN을 사용하는 경우 모델이 cheating을 해서 batch를 섞어준 뒤에 GPU에 batch를 쪼개서 할당했다고 합니다.
4. Experiments
ImageNet-1M, Instagram-1B을 학습에 사용했다고 합니다. ImageNet-1M은 흔히 알려진 ImageNet1K입니다. 그런데 여기선 라벨을 따로 사용하지 않으니 이미지 갯수 기준으로 명명했다고 합니다.
실험 결과는 일부만 소개해드리도록 하겠습니다. Backbone(encoder)은 ResNet50을 사용하였습니다.
4.1. Linear Classification Protocol
Query encoder를 가져와서 freeze한 상태로 linear classifier를 학습시킨 세팅입니다. 위의 세 가지 방법을 비교하였습니다.

End-to-end는 dictionary가 batch size에 종속적이라서 x축의 크기를 다른 방법 만큼 늘리지 못했습니다. 결과적으로 MoCo가 가장 좋은 성능을 보였습니다.

위 표는 momentum 비율을 가지고 실험한 결과입니다.

위는 기존에 소개된 모델들과 ImageNet을 가지고 성능비교를 한 것 입니다. 좋은 성능을 보이고 있습니다. 논문의 table1에 각 모델이 어떤 backbone을 썼는지 나오니 궁금하신 분들은 참고하기실 바랍니다.
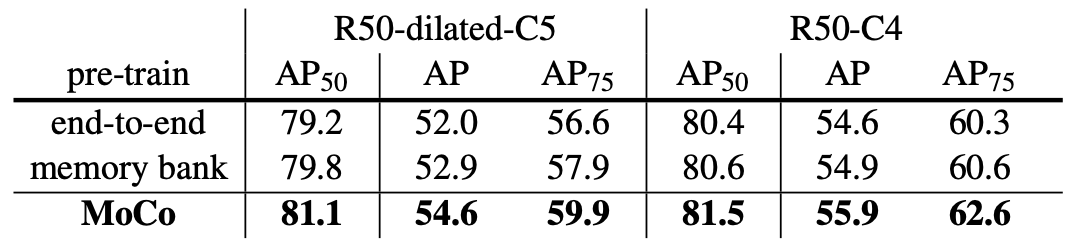
위 표는 Pascal VOC object detection task에 대한 결과입니다.
'Computer Vision' 카테고리의 다른 글
| [논문 리뷰] Segment Anything (4) | 2023.04.12 |
|---|---|
| [논문 리뷰] End-to-End Object Detection with Transformers (DETR) (0) | 2023.02.10 |
| [논문 리뷰] YOLOv4 (YOLOv4: Optimal Speed and Accuracy of Object Detection) (0) | 2022.10.25 |