안녕하세요. 오늘 리뷰할 논문은 Meta AI(FAIR)에서 발표한 Segment Anything이라는 논문입니다. Linked In 같은 곳에서 Segment Anything을 발표한지 몇 시간도 되지않아 굉장히 많은 추천을 받으며 화제가 되고 있습니다. Segment Anything은 대용량 데이터셋을 가지고 자연어 및 다양한 지시로 Image Segmentation task를 수행할 수 있도록 하는 프로젝트입니다.
Segment Anything
Meta AI Computer Vision Research
segment-anything.com
https://github.com/facebookresearch/segment-anything
GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (S
The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. -...
github.com
0. Abstract
해당 논문에서는 Segment Anything(SA) 프로젝트를 제시하였습니다. 여기서는 image segmentation task를 위한 새로운 task, model, dataset을 제시하였습니다. SA 프로젝트의 데이터셋(SA-1B)은 10억개 이상의 mask, 1,100만 장 이상의 저작권을 준수한 이미지로 구성되어있다고 합니다. SAM(Segment Anything Model)은 대용량 데이터셋에 자연어 및 다양한 지시를 prompt로 받아서 image segmentation 수행하도록 학습이 되었기 때문에 zero-shot setting에서도 준수한 성능을 보여주었다고 합니다.
1. Introduction
기존의 NLP와 VL 모델들이 충분한 양의 데이터를 가지고 모델을 학습시키면 모델이 새로운 데이터 분포에도 근 하자 없이 잘 작동한다는 것을 보여왔습니다. VL쪽에서는 constrastive learning을 활용하여 CLIP과 ALIGN 같은 모델이 제안된 바 있습니다. 이러한 모델을은 zero-shot 성능도 훌륭하지만 backbone으로 사용하는 등의 방식으로 여러 downstream task에 사용했을 때도 좋은 성능을 보입니다. 논문에서 따로 언급하진 않지만 NLP 쪽에서는 GPT가 이런 모델의 예가 될 수 있을 것 같습니다. SA 프로젝트에서는 image segmentation 분야에서의 foundation model을 제안하는 것이 목표라고 이야기합니다.
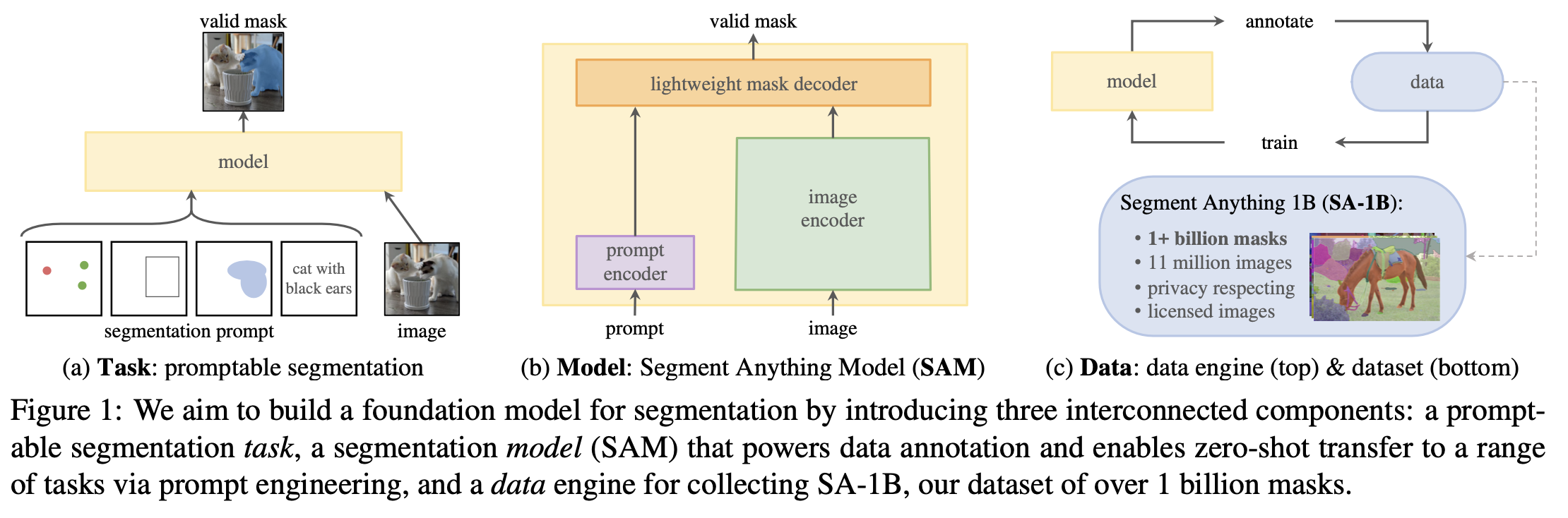
이러한 목표를 성취하기 위한 방법을 크게 세 가지로 구분해서 접근할 수 있습니다.
Task (Promptable segmentation task)
자연어 및 다양한 지시를 통해 지시가 가능(promptable)해야하고 여러 downstream task에도 잘 맞으여 generalizaability가 뛰어나야합니다. 위 그림의 (a)를 보시면 prompt는 자연어나 bounding box나 대상에 점을 찍는 방식 등이 될 수 있으며 사용자가 모델에게 어느 부분을 segmentaion하고 싶은지 알려주는 일종의 수단입니다.
또한 prompt가 모호하더라도 충분히 합리적인 결과 값을 내놓아야합니다. 모호한 prompt의 예시로, 경우는 흰 셔츠를 입고있는 남성의 이미지가 있다고 가정해보겠습니다. 사용자가 흰 셔츠에 점을 찍고 segmentation을 해달라고 하면 셔츠만 segmentation을 해달라는 것일 수도 있고 사람 전체를 segmentation 해달라는 의미일 수도 있는데 "셔츠+사람의 일부"만 segmentation하는 식으로 애매한 결과가 나오지 않도록 하는게 목표였습니다.
Model
위와 비슷하지만 사용자와 상호작용(interactive use) 수준의 속도(real-time)이면서 다양한 prompt를 받아서 segmentation mask를 반환할 수 있어야 합니다. 모호성한 prompt도 눈치껏 잘 처리해야합니다.
SAMdms image encoder/fast prompt enoder/mask decoder로 나누어져있습니다. 한 이미지에 여러 개의 prompt를 사용하였으며, 모호성 문제를 처리하기 위해서 segmentation은 여러개를 할 수 있도록 하였습니다. 모델은 웹상에서 서비스를 할 때 50ms 이내에 브라우저에 masking 값이 리턴된다고 합니다.
Dataset
모델이 zero-shot capability를 가질 수 있도록 충분하고 다양한 데이터가 필요합니다. VL model들처럼 Web기반의 dataset을 약간의 가공만 거친 뒤 바로 사용하면 좋겠지만 image segmentation은 Ground Truth로 사용할 mask를 라벨링해주어야 하기에 불가능합니다. 이 문제를 처리하기 위해 저자들은 data engine(위 이미지의 (c)부분)이라는 것을 사용했다고 합니다.
Data Engine
위에서 언급했던 양과 질의 데이터를 웹에서 구하기 위해서 data engine은 크게 assisted-manual, semi-automatic, fully automatic 단계로 구분이 된다고 합니다. 자세한 설명은 뒷 부분에서 하도록 하겠습니다.

2. Segment Anything Task
Task
위에서 말했듯이 ambigous prompt에 대해서 고개를 끄덕일만한 결과를 내도록 하는 것이 목표입니다. 아래 그림이 ambiguous prompt에 대한 예시입니다.

Segmentation Anythin Task 부분에서 하는 말이 앞에서 나온 말들과 대부분 겹치는 말이기 때문에 넘어가도록 하겠습니다.
3. Segment Anything Model (SAM)
SAM은 크게 세 부분으로 이루어져있습니다.
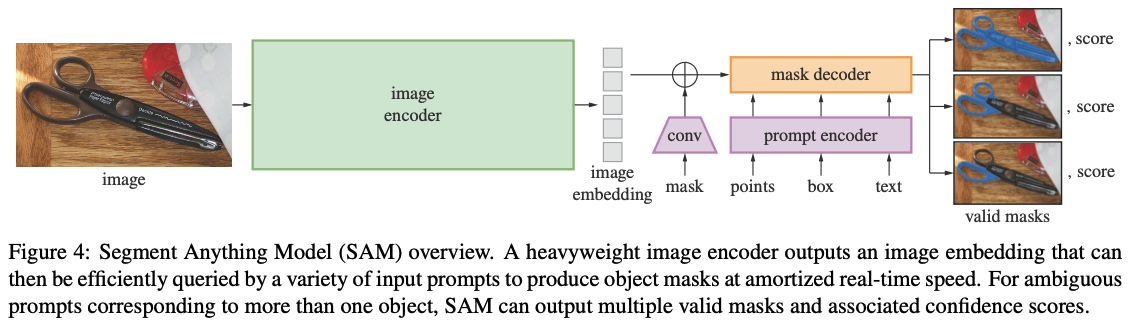
Image Encoder
MAE 기반으로 사전학습된 ViT를 사용했습니다. 실제로 demo에서 사용되고 있는 모델은 632M개의 파라미터를 가지고 있는 것으로 보아 ViT-H를 사용하고 있는 것 같습니다.
Prompt Encoder
Prompt는 sparse(points, boxes, text)와 dense(mask) prompt로 분류됩니다. Point나 box는 positional encoding처럼 표현하며 text는 CLIP의 text encoder를 사용해서 구합니다. Mask는 convolution 연산을 한 후에 이미지 embedding에 더해집니다.
코드는 아래 부분에 있습니다.
GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (S
The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. -...
github.com
제가 못 찾은 것일 수도 있지만 CLIP을 사용해서 text encoding을 하는 부분은 23/04/10 기준 코드 상으로 따로 구현되어있지는 않은 것 같습니다. 7.5장 zero-shot text-to-mask 부분에서 CLIP을 통해서 text를 SAM에 사용할 수 있다는걸 간단하게 PoC만 하고 넘어갑니다.
Mask Decoder
해당 부분은 segmentation map을 찍는 부분입니다. Mask Decoder는 image embedding, prompt embedding, output token을 받아서 mask 형태로 반환합니다. 구조는 Transformer Decoder를 변형한 형태입니다. Mask Decoder 안에서는 prompt embedding에 대해 self-attention, prompt embedding과 image embedding 간에 양방향으로 cross-attention을 수행한다고 합니다. 모든 embedding들이 업데이트 됩니다. 두 층이 통과되고 MLP를 통해 masking probability를 반환하는 형식입니다.
Resolving Ambiguity
앞서 언급했던 모호성 문제를 해결하기 위해서 모델이 3개의 mask prediction을 하도록하였습니다. 학습을 할 때는 세 개 중에서 estimated IoU를 사용한 confidence score를 구해서 랭킹을 매긴 후 가장 점수가 높은 결과에 대해서만 loss에 태워 학습을 했다고 합니다. 3 이라는 숫자는 휴리스틱하게 3개의 prediction 정도면 어느정도 모호성 문제가 해결된다고 저자들은 봐서 그렇게 정해졌습니다.
Losses and Training
Focal loss와 dice loss를 같이 사용하였습니다. 이 부분은 생소해서 잘은 모르겠는데 prompt를 랜덤 샘플링해서 mask당 11 round가 돌도록 interactive sestup을 했다고 합니다.
4. Segment Anything Data Engine
Assisted-manual stage
SA-1B dataset을 구축하는 첫 번째 단계입니다. 전문 annotator 팀이 segmentation model과 상호작용하는 식으로 masking dataset을 구축합니다. Annotator들을 SAM 기반의 모델을 사용하는 브라우저 기반 마스킹 툴을 사용하며, 픽셀 단위로 마스크를 조절할수 있습니다. 이 때 마스킹 대상이 되는 이미지들은 사전에 모두 SAM의 image encoder가 embedding을 미리 계산해놓은 상태로, 라벨링 툴 사용 시 지연 시간이 거의 없었다고 합니다. Annotator들은 각자 이미지 하나 당 30초 동안 마스킹을 하였습니다.
가장 초반의 SAM은 기존에 제공되는 image segmentation dataset으로 훈련이 된 상태입니다. Annotator들에 의해 충분히 마스킹 데이터가 갖춰졌다고 판단된 시점에 새로운 데이터로 SAM을 재학습했다고 합니다. 그리고 데이터가 모임에 따라서 image encoder도 ViT-B에서 ViT-H로 점차 크기를 키웠다고 합니다. 총 6번의 재학습이 있었으며, annotation을 할 때는 mask당 34초에서 14초로 줄었으면이는 COCO mask annotation을 할 때보다 6.5배 빠른 시간이라고 합니다.. 또한 extreme point로 bounding box를 치는 것보다 2배 정도 밖에 차이가 나지 않았다고 합니다. 해당 단계에서 120만 장의 이미지에 대해서 430만 개의 마스크를 만들었다고 합니다.
Semi-automatic stage
해당 단계에서는 mask를 다양하게 만들어 내는 것에 초점을 두었습니다. 이 때 annotator들은 이미지에서 덜 부각되는 객체에 대해 집중하도록 하였습니다. 이 때 이미지에서 눈에 먼저 들어오는 객체가 아닌 그 외의 객체도 mask GT를 만들기 위해 먼저 모델로 confident score가 높은 눈에 먼저 들어오는 객체들의 segmentation mask는 제외하고 마스킹을 하도록 지시를 하였다고 합니다. 이 단계에서 180만장의 이미지에서 590만개의 마스크를 얻었다고 합니다. 이 단계에서도 마찬가지로 데이터가 어느정도 쌓일 때마다 누적하여 모델을 새로(총 5 회) 학습하였다고 합니다.
Fully automatic stage
1, 2 단계에 걸쳐 모델의 성능이 올라온 동시에 ambiguity aware하게 학습이 되었기 때문에 해당 모델을 가지고 완전 자동화된 방식으로 mask를 생성하였다고 합니다. 최종적으로 11억 개의 고품질 mask를 얻었다고 합니다.
5. Segment Anything Dataset
데이터셋에 대한 소개를 하고 있는데 기본적인 부분은 넘어가도록 하겠습니다.

Mask의 위치 분포를 보면 다른 데이터셋과 비슷하거나 더 고르게 분포되어있는 것을 확인할 수 있습니다. Open Images 같은 경우에는 보통 사진을 찍는 사람이 피사체를 중앙에 두고 찍기 때문에 위와 같은 분포가 나오데 됩니다.


뒷 부분에서는 RAI analysis, Zero-shot experiments 등을 다루고 있는데 궁금하신 분들은 논문을 참고하시면 좋을 것 같습니다.