안녕하세요. 오늘 리뷰해볼 논문은 NeuMAN: Neural Human Radiance Field from a Single Video이라는 논문입니다. ECCV2022에 나온 논문입니다. 적은 시간의 비디오만 가지고 NeRF에 인간의 모습을 학습 시킨 뒤 자유롭게 렌더링하는 것을 목표로 하는 연구입니다. 저도 이 도메인의 페이퍼를 많이 읽어보진 않았기에 미숙한 부분이 있어도 양해부탁드립니다.
(https://arxiv.org/abs/2203.12575)
0. Abstract
해당 논문의 저자들은 하나의 임의의 비디오를 가지고도 novel human pose와 scene을 렌더링할 수 있는 프레임워크를 제안합니다. 비디오는 움직이는 카메라로 찍은 비디오(핸드폰 같은)이며 human NeRF와 scene NeRF를 각각 사용한다고 합니다. 각각의 모델을 학습하기 위해서 다양한 방법을 사용하여 비디오 프레임에서 rough한 정보들을 뽑아냅니다. 가령 아래 나오겠지만 detection model이나 depth estimation model, SMPL 같은 것들을 비디오 프레임에 사용하고, 그 결과를 NeRF 학습에 사용합니다. 해당 메서드를 사용하면 10초 남짓한 비디오 클립에서도 옷의 주름, 악세사리 등의 디테일을 잘 기억하여 새로운 인간의 동작을 생성할 수 있다고 합니다. 프레임 상의 RGB space 상의 인간 픽셀을 canonical space로 투사한 뒤에 해당 정보를 가지고 human NeRF를 학습한다고 합니다.
(https://github.com/apple/ml-neuman)
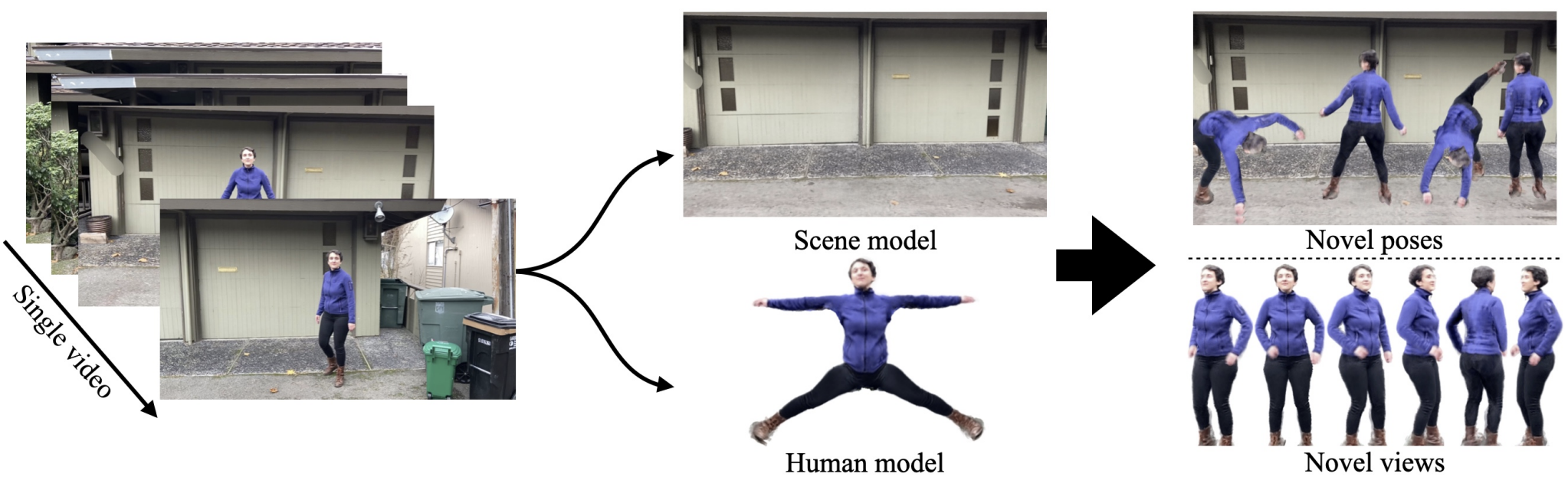
1. Introduction
앞서 말했던 것처럼 해당 논문에서는 multi-camera, manual annotation 같은 것 없이 비디오 클립만 가지고 human model/scene model을 학습하는 것을 목표로 하고 있습니다. Human model은 비디오에는 없는 새로운 포즈를 렌더링을 할 수 있으며 scene model은 정적인 배경을 렌더링합니다.

저는 위 표에서 언급된 비교 대상이 된 모델에 대해서는 잘 모르지만 저자들에 의하면 Neuman은 기존 연구들과 비교했을 때 가장 제약된 세팅에서 가장 어려운 task를 수행한다고 이야기 합니다. Neuman에서는 학습에 필요한 human pose, human shape, human masks, camera pose, sparse scene, depth map 같이 학습에 필요한 정보를 기존에 제시된 방법들을 사용하여 구했다고 합니다.
Masked-RCNN을 사용하여 human과 scene의 mask를 구하였으며 scene NeRF에 사용하기 위해 colmap과 다른 deep learning model을 사용하여 depth map estimation을 했다고 합니다. Human NeRF는 SMPL을 사용하여 RGB space가 아닌 canonical space에서 pose independent하게 학습하였다고 합니다. 하지만 SMPL을 그대로 가져와서 사용하면 미세한 부분을 잘 잡지 못하는 경우가 있어서 human NeRF를 학습할 때 SMPL도 end-to-end로 학습을 하였다고 합니다. 그리고 SMPL이 잡지 못한 부분을 잡기 위해 correction network를 따로 사용하였다고 합니다.
2. Related Work
NeRF와 Neural Rendering of Humans에 관한 내용입니다. 관심 있으신 분은 원문을 보시면 좋을 것 같습니다.
3. Method
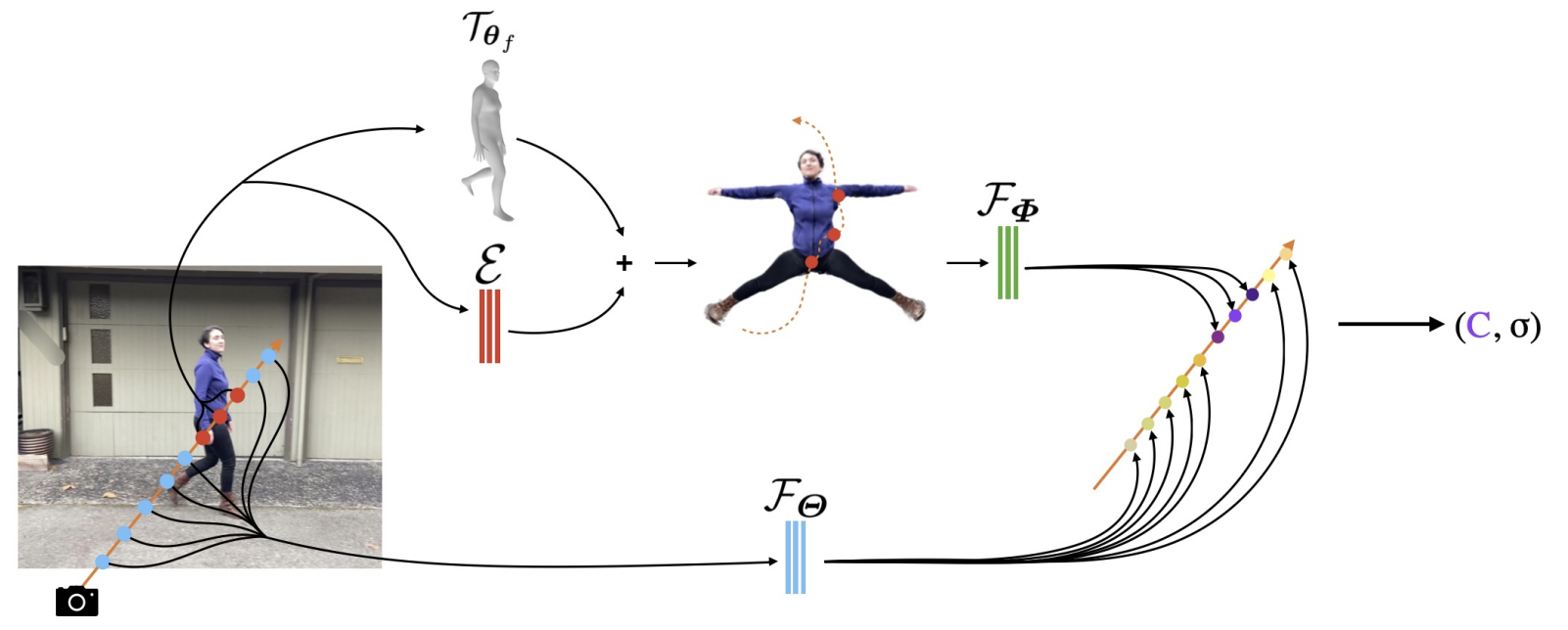
Neuman의 구조입니다. 아래는 scene NeRF이며 위는 SMPL, correction model을 통과하여 인간을 canonical space에 투영 한 후 human NeRF를 통과하는 것입니다.
3.1. The Scene NeRF Model
Scene NeRF는 아래와 같은 loss들을 사용하여 학습을 합니다.
\(M(r)\)은 Mask-RCNN을 통해 얻은 human segmentation map입니다. 지금은 배경을 학습해야하기에 \(1-M(r)\)이라 적혀있으며, 배경 pixel에 대해서만 loss 계산이 됩니다. 그리고 뒤 쪽에 있는 term은 NeRF와 동일하게 RGB pixel estimatio을 하여 loss를 계산한 것입니다.

Video-NeRF과 동일한 부분인데, 위의 loss만 가지고 학습을 진행하면 배경의 pixel을 estimation할 때 'hazy' object 같은 것들이 함께 보인다고 합니다. 이런 현상은 당연하겠지만 ray 상에서 대상과 카메라 사이의 공기 중에 미세한 픽셀값들이 껴있기 때문에 그렇습니다. 그래서 Video-NeRF에서 한 것과 동일하게 비어있는 공간(허공)에서는 density을 0으로 예측하도록 하는 regularizer를 사용하였다고 합니다. 아래 보이는 \(\hat{z_{r}}\)은 논문 상에서 \(D_{fuse}(r)\)이라고도 쓰여있습니다. \(D_{fuse}(r)\)은 쉽게 말하면 '물체가 있을 법한 거리'라고 생각하시면 됩니다. 그래서 아래 식을 보면 \(t_n\)부터 \(a(가중치)*(물체가 있을 법한 거리)\) 사이는 최대한 아무것도 없도록 하는 regularizer입니다. 앞에 가중치는 혹시 모를 오차를 대비해서 넣어주는 듯 합니다.

\(D_{fuse}(r)\)는 COLMAP과 depth map estimaiton 모델들을 사용하여 depth map 만든 뒤 구한다고 합니다. Mask-RCNN을 통한 segmentation map은 human mask를 4%정도 dilate해서 좀 넉넉하게 masking을 한다고 합니다.
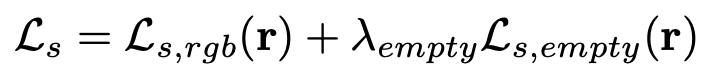
전체 loss는 앞서 언급된 두 loss를 합친 형태입니다. 모델이 여러 개의 프레임을 통해서 학습되기 때문에 특정 프레임에서 배경이 마스킹 되어있어도 학습이 됩니다.
3.2. The Human NeRF Model
저자들은 canonical space 상에서 大(대)자 SMPL을 정의하였습니다. 풀어말하면 SMPL 상에서 인간의 외형을 가져올 때 팔, 다리를 큰 대 형태로 가져오겠다는 말입니다. 기존의 T-pose 형태는 다리가 붙어있기 때문에 두 다리가 volume을 연산할 때 제대로 분리되지 않는 경우가 있다고 합니다.
아래 나오는 \(x_f\)는 f 번 째 프레임을 의미하고, \({\tau}_{{\theta}_f}(x_f)\)는 SMPL을 통해 얻어진 mesh입니다. \({\varepsilon}\)은 correction network입니다. MLP로 되어있습니다. 이를 통해 RGB로 된 observation space에서 canonical space로 warping이 되게 됩니다.

가장 왼쪽 이미지는 원본, 그 다음은 ROMP를 사용한 estimation, 그 다음은 SMPL을 통한 estimation이며 마지막은 corretion network까지 end-to-end로 학습한 결과입니다. 고개의 각도 같은 부분을 correction network를 통해 더 올바르게 보정한 것을 볼 수 있습니다.

하지만 위 쪽 neuman architecture 이미지를 보시면 input으로 들어가는 ray는 일직선인데 비해 canonical space로 투사된 human mesh는 투사 과정에서 직선이 아닌 곡선 형태로 바뀌어 왜곡이 생긴 것을 볼 수 있습니다. 이를 교정하기 위해서 아래와 같은 텀을 사용하였습니다.

최종적으로 human NeRF는 아래와 같은 형태를 띄게 됩니다.

위 human NeRF를 학습하기 위해서는 다음과 같은 Loss들이 사용되었습니다.
마찬가지고 RGB 값을 estimation 하면서 loss를 구하는 과정입니다. 기존 NeRF와 방식은 같습니다.

따로 식으로 적히진 않았지만 32x32 패치로 나누어 LPIPS를 계산하는 LPIPS loss도 사용했다고 합니다. 그리고 \({\alpha}_h\)는 ray 상에서 density를 누적한 값 입니다. Mask loss는 rendering 했을 때 객체가 반투명해 보이지 않도록 하게 하기 위해, human masking이 된 영역에서 density를 최대한 높게 나오도록 합니다.
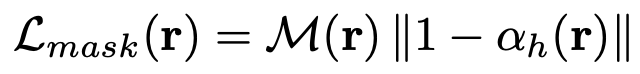
SMPL을 통해 얻은 mesh의 안쪽은 volume이 있고, 바깥 쪽은 비어있도록 하는 loss 입니다.
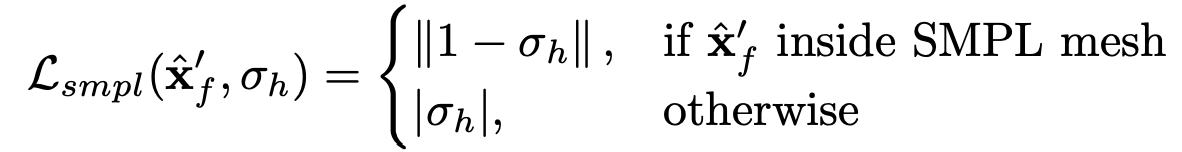
아래 loss는 canonical human을 구할 때 0 혹은 1의 값만 갖도록 하여 human 주변이 일렁이는 것처럼 보이지 않도록 하는 loss입니다. w는 투명도를 나타냅니다.

아래 loss는 hard loss와 마찬가지로 mesh human의 결과를 더 sharp하게 만들기 위한 loss입니다. Alpha compositing한 값이 0 혹은 1이 나오도록 합니다.

제시된 loss term들이 모두 합쳐져서 아래처럼 사용되고, human NeRF를 학습하는데 사용됩니다.
