안녕하세요. 오늘 리뷰해볼 논문은 LERF: Language Embedded Radiance Fields입니다. LERF는 주어진 scene에서 자연어를 통해 대상을 찾아내고 NeRF처럼 해당 객체에 대해 입체적인 모습은 추론하는 모델입니다.
https://arxiv.org/abs/2303.09553
LERF: Language Embedded Radiance Fields
Humans describe the physical world using natural language to refer to specific 3D locations based on a vast range of properties: visual appearance, semantics, abstract associations, or actionable affordances. In this work we propose Language Embedded Radia
arxiv.org
https://www.lerf.io/#coming_soon
0. Abstract
Language Embedded Radiance Fields(LERFs)는 CLIP 같은 멀티모달 모델의 language embedding을 NeRF 안에 집어넣은 모델입니다. LERF는 CLIP의 embedding을 NeRF로 volume rendering하는 방식으로 language field를 배우게 됩니다. LERF는 실시간으로 자연어를 통해 상호작용이 가능하며 3차원 상에서 자연어와 관계가 높은 객체를 대상으로 하는 3D relevancy map을 제공하기도 합니다. 해당 task가 어떤 것인지는 위에 나온 프로젝트 페이지에 가보시면 한 눈에 이해가 갈 것 입니다.
1. Introduction
기존의 NeRF는 특정 3D scene을 실제 같이 유추할 수 있는 모델이었습니다. 이 과정에서 해당 물체가 무엇인지 등의 의미적인 부분은 고려하지 않았습니다. 하지만 LERF에서는 자연어를 인간의 가장 자연스러운 인터페이스라고 정의 하면서 3D scene을 자연어를 통해 이해할 수 있도록 하였습니다. 여기서 CLIP을 사용하면서 단순한 객체의 종류 뿐만 아니라 객체의 쓰임세, 고유한 캐릭터 등 굉장히 폭넓은 범위의 자연어를 이해할 수 있도록 하였습니다.
동시에 다양한 크기의 물체, long-tail term (흔하지 않은 단어), 추상적인 단어까지 이해할 수 있도록 학습하였다고 합니다. 아래 그림을 예를 들어 노랑, 전기, waldo(캐릭터) 등의 단어도 잘 캐치해내는 것을 확인할 수 있습니다.

LERF는 position, physical scale을 입력으로 받아서 NeRF와 language field를 joint한 방식으로 학습을 하고, CLIP vector를 뱉어냅니다. 학습을 할 때는 scene에서 multi-scale 이미지를 CLIP에 태워 CLIP embedding을 얻고 이를 피라미드처럼 쌓아서 LERF의 supervision으로 준다고 합니다. 이를 통해서 LERF는 scene 안에 있는 다양한 크기의 객체들을 인식할 수 있다고 합니다.
2. Related Work
Open-Vocabulary Object Detection, Distilling 2D Features into NeFR, 3D Language Grounding과 관련된 내용이 나옵니다.
3. Language Embedded Radiance Fields
위 그림은 LERF의 구조입니다. 저자들은 CLIP이 embedding은 입력 이미지 전체에 대한 embedding을 구해주지만 NeRF는 픽셀 단위의 계산을 하기 때문에 CLIP embedding으로 supervision을 주기 위한 새로운 방법이 필요하다고 합니다. 해당 논문에서는 이를 위해 위 그림처럼 multiscale CLIP Features를 averaging 하여 구해줍니다. 그리고 point-by-point supervision을 주는 대신 input coordinate을 중심으로 하는 volume을 구하고 volume과 CLIP feature을 비교합니다.
3.1. LERF Volumetric Rendering
NeRF에서는 position x와 direcction d를 입력으로 받고 color c, density 값을결과 값으록 받습니다. 이 값을 alpha compositing 하여 input으로 받았던 위치의 pixel 값을 구합니다. LERF에서는 NeRF의 결과 값과 position, scale 값을 입력으로 받는 language embedding model의 결과 값을 함께 사용한다고 합니다. 객체의 위치가 가지는 맥락적인 의미가 보는 방향에 상관 없이 유지되도록 하게 하기 위해서 language embedding을 구하는 모델에서는 viewing direction d를 사용하지 않았습니다. Language embedding model에서 받는 scale 값은 위 그림에서도 나오는데 position x를 중앙으로 두고 만든 가상의 cube의 가로 길이입니다. scale 값은 카메라로부터 거리가 멀어질 수록 커지며, 해당 아이디어는 Mip-NeRF의 conical frustum과 유사하다고 합니다.
LERF의 rendering weight는 NeRF와 같은 방식으로 계산이 됩니다.
해당 weights를 가지고 아래와 같이 LERF의 language outputs을 구합니다. LERF는 카메라가 바라보는 방향에 대해 volume rendering 하여 CLIP representation space 상에 존재하는 output을 만들어 낸다고 이해하였습니다.
3.2. Multi-Scale Supervision
위에서 구한 Lauguage embedding(F out)을 CLIP encoder를 학습시키는 것처럼 joint하게 학습시키기 위해 이미지에 대한 CLIP embedding을 구하는 과정을 거칩니다. Scene에서 다양한 크기의 객체를 잡아낼 수 있도록 하기 위해 volume과 겹쳐있는 영역에 있는 다양한 크기의 이미지를 사용합니다. 위 그림처럼 다양한 크기의 이미지의 CLIP Embedding을 구하여 해당 embedding들에 대한 trilinear interpolation을 하여 위에서 구한 language output에 supervision을 줄 수 있는 ground truth를 구합니다. 이렇게 구한 GT와 위에서 구한 language output의 similarity을 줄이는 방향으로 모델을 학습합니다.
3.3. DINO Regularization
지금까지 나온 방법만으로 LERF를 사용하면 아래 그림의 w/o DINO처럼 relevancy map을 찍어보았을 때 language prompt query를 넣었을 때 정교하지 못했다고 합니다. 이를 개선하기 위해 Vision transformer를 Self-supervised learning으로 학습한 DINO를 사용했다고 합니다.
위에 나온 LERF의 구조에서 LERF DINO Feature를 결과 값으로 뱉는 것을 볼 수 있습니다. Position x를 받는 F_DINO 모델이며 DINO Feature를 학습하도록 되어있습니다. DINO는 CLIP과 다르게 pixel-aligned feature이기 때문에 scale 값을 넣어서 volume을 구할 필요는 없다고 합니다. 이 때 MSE Loss를 통해 실제 DINO의 feature 값을 GT 삼아서 학습을 한다고 합니다.

DINO feature가 inference를 할 때에 직접적으로 사용이 되진 않지만 CLIP embedding을 계산하는 모델과 backbone을 공유하도록 설계하여 regularization 효과를 주었다고 합니다. 위처럼 결과적으로 객체를 더 선명하게 잡아내는 것을 볼 수 있습니다.
3.4. Field Architecture
위의 설명을 통해 유추할 수 있겠지만 LERF의 구조는 크게 두 개의 구분된 네트워크로 이루어져있습니다. 하나는 DINO와 CLIP feature를 계산하는 네트워크이고 다른 하나는 density와 color 값을 유추하는 일반 NeRF입니다. 앞에서 나왔던 것처럼 NeRF의 weight를 가지고 CLIP embedding(language embedding)를 계산합니다. 그래서 학습 시 L_DINO와 L_lang의 graident가 NeRF에는 영향을 주지 못합니다. NeRF의 구조는 Nerfacto의 구조를 동일하게 사용했다고 합니다.
3.5. Querying LERF
LERF는 자연어가 open-ended하고 ambiguous하다는 특징(정해진 카테고리 같은 것이 없음, 한국말로 적당한 말을 생각이 나지 않습니다.)을 활용하여 임의의 text prompt를 통해 3D relevency map을 유추하는 방법을 제안합니다.
LERF에 Query를 사용하는 방법은 크게 두 부분으로 나누어져있습니다.
1) Rendering된 embedding으로 relevancy score 구하기
2) 주어진 prompt를 사용하여 scale 구하기
Relevancy Score:
저자는 중립적인 단어들을 골라서 canonical phrase라고 칭했습니다. 여기에는 object, things, stuff, texture 정도가 있습니다.
이러한 canonical phrase의 CLIP embedding, language CLIP embedding, query CLIP embedding을 가지고 query와 language embedding 간의 거리를 구합니다.
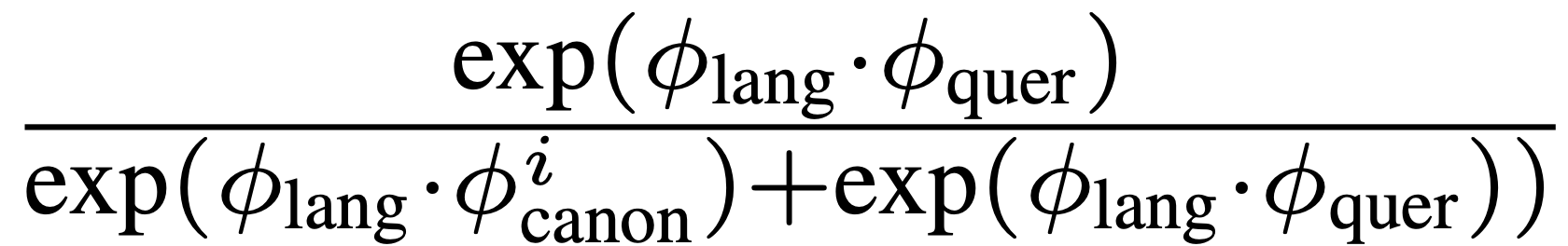
Scale Selection:
LERF는 모든 query에 대해 relevancy map을 계산하여 가장 높은 relevancy score가 나오는 scale을 선택한다고 합니다.
Visibility Filtering:
배경 같은 것들은 학습 시에 view가 충분하지 않아서 embedding이 noisy하게 만들어진다고 합니다. 이를 해결하기 위해 querying을 할 때 training view가 5개 이하인 샘플은 버렸다고 합니다.
이 후 부분은 간단하게 이야기 하도록 하겠습니다.
4. Experiements
4.1. Qualitative Results

다른 모델과 비교를 하면 위처럼 LSeg에서 잘 "glass of water"는 잘 찾아내지만 "Egg"는 찾지 못하는 것이 LSeg는 COCO dataset에서 학습이 되었기 때문이라고 합니다. COCO dataset에 없는 class는 잡아내지 못하는 치명적인 단점이 있는 것입니다. 비슷한 맥락으로 아래 그림을 보면 자주 등장하지 않는 cookbook 같은 객체는 LERF만 찾아내는 것을 볼 수 있습니다.

4.2. Existence Determination
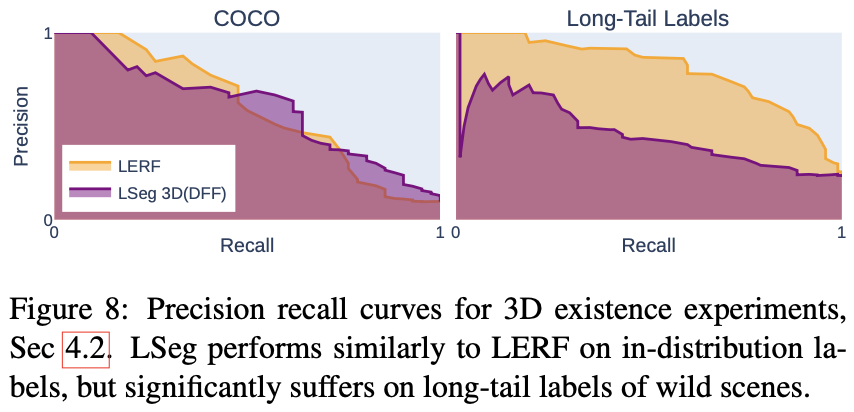
위에서 언급했던 것처럼 LERF는 다른 모델에 비해 long-tail object를 잘 잡아내는 것을 확인할 수 있습니다. 이는 CLIP의 representation space을 사용했기 때문이라고 볼 수 있을 것 같습니다.