오늘은 GIRAFFE를 리뷰해보겠습니다. GIRAFFE는 2021년 CVPR best paper였던 논문입니다. GIRAFFE는 이미지를 객체 단위로 피처를 생성한 뒤 이를 합친 뒤 이미지로 생성해내는 모델입니다. 이 때 이미지에 합성될 객체들의 피처를 생성해서 합치는 부분까지가 NeRF와 유사한 구조를 띄고 있습니다.
아래 그림을 참고하면 이해에 도움이 될 것 같습니다. 각 객체는 shape, appearance, pose latent code를 가지고 feature 형태로 만들어진 후 volume rendering을 통해 하나로 합쳐지게 됩니다. 이미지 대신 feature를 만드는 것이기 때문에 neural radiance field 대신 neural feature field라고 부르는 듯 합니다.

0. Abstract
저자들은 생성모델이 사진 같은 이미지를 생성하는 것 말고도 생성하는 이미지 안의 내용이 조종이 가능해햐한다고 이야기합니다. 그리고 이런 이미지를 생성하는 모델을 만들기 위해서는 모델이 scene을 2D가 아닌 3D로, 이미지 내의 객체 별로(compositional하게) 이해할 수 있어야한다고 가정합니다. 저자들을 NeRF pipeline을 통해 이를 가능하게 하였으며, 이미지 내의 개별 객체의 모양, 크기 위치 등을 성공적으로 조절하는 모습을 보였습니다.
1. Introduction
최근 생성 모델들은 고해상도로 굉장히 현실적인 이미지를 만들어내는데 성공했습니다. 하지만 진짜 같은 이미지를 만드는 것 만큼 중요한 것이 원하는 이미지를 만드는 것입니다. 물론 이 문제를 해결하기 위해서 다양한 시도들이 시도된 바가 있지만 저자들은 대부분의 시도에서 모델들이 2D domain representation만을 가지고 학습한다고 지적합니다. 저자들은 latent code를 가지고 이미지 내 개별 객체를 조절할 수 있는 NeRF기만 생성모델을 제안했습니다.
Latent code를 통해서 개별 객체를 생성하기에 이미지를 자유롭게 조작할 수 있고 NeRF 기반으로 생성 모델을 학습하기 때문에 3D 상의 지식을 학습할 수 있었다고 합니다. 저자들은 GIRAFFE의 contribution을 아래와 같이 소개합니다.
- Compositional 3D scene representation을 generative model에 학습하여 이미지 조작이 용이한 모델을 제안했다고 합니다.
- 위를 NeRF pipeline을 사용하여 빠르고 실제적인 생성이 가능해졌다고 합니다.
추가로 NeRF와는 다르게 픽셀을 바로 생성하는게 아니라 비교적 차원수가 적은 feature를 생성하기에 훨씬 컴퓨팅 자원을 덜 사용합니다. (Feature를 이미지로 변환하는 decoder는 간단하고 가벼운 모델을 사용합니다. )
2. Related Work
GAN, Implicit Functions, 3D-Aware Image Synsthesis에 대해 다루고 있습니다. 관심이 있으신 분들은 논문의 해당 부분을 읽어보시면 좋을 듯 합니다.
3. Method
저자들은 별도의 supervision(라벨들) 없이 이미지 만으로 위에서 언급한 모델을 만드는 것이 목표였다고 합니다. 이러한 목표를 이루기 위해 모델 pipeline을 아래와 같이 구성하였습니다.
개별 객체를 Neural Feature Field를 통해 모델링하는 부분 (3.1)
3.1에서 만든 여러 개의 객체를 합친 composite scene으로 만드는 부분 (3.2)
Rendering을 위한 volume rendeing, neural rendering을 활용한 방식 (3.3)
모델 학습 방법 (3.4)
모델의 구조는 아래와 같습니다.

3.1. Object as Neural Feature Fields
Neural Radiance Fields: NeRF는 3차원 좌표 x, 2차원의 viewing direction(d)을 density와 RGB 값으로 mapping하는 함수 f라고 볼 수 있습니다. 이 과정에서 입력 값에 아래와 같은 positional encoding을 하게 됩니다. t에 x, d 값이, L은 주파수를 의미하나다고 합니다.

여러 층의 MLP로 이루어진 f(NeRF)는 아래와 같은 Input/ouput 형태를 띕니다. Positional encoding이 된 input이 들어가면 density와 RGB 값이 나온다는 의미입니다.
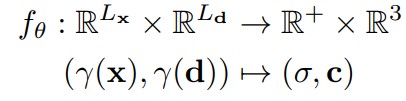
Generative Neural Feature Fields: NeRF가 파라미터를 pose를 독립 변수로 두고 학습했다면, Generavie model for Neural Radiance Fields(GRAF)는 따로 camera pose가 없는 일반 이미지 데이터셋을 가지고 학습을 하였습니다. 입력으로 들어가는 Z는 임의로 만들어진 shape, appearance condition이며 입력값으로 들어갈 때 latent M으로 매핑됩니다. 이미지를 생성하는 condition처럼 작동합니다.
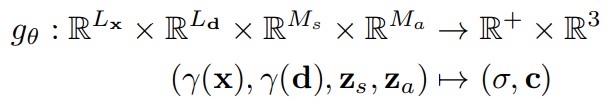
GIRAFFE는 GRAF의 formulation을 아래와 같이 바꾸었습니다. GIRAFFE는 앞서 말씀드렸던 것처럼 이미지를 생성하지 않고 이미지를 만들기 위한 feature를 먼저 생성하기 때문에 결과 값이 density, feature(RGB pixel이 아닌)이 되고 그래서 차원도 다르게 표기 되어있습니다.

Object Representation: 저자는 NeRF나 GRAF의 가장 큰 한계가 전체 scene을 하나의 모델로 생성하려한다는 것이라고 합니다. GIRAFFE는 scene 안에 존재하는 객체의 pose, shape, appearance 등을 개별적으로 조절하기 위하여 개별적인 feature field를 사용하여 생성한 후 합치는 과정을 거쳤다고 합니다. NeRF의 radiance field가 여기에서 feature field에 대응되는 부분이라고 보시면 될 것 같습니다.

위는 R, s, t 순으로 rotation, scale, translate을 나타내는 translation parameter입니다. 아래와 같은 식으로 사용됩니다.

3.2. Scene Composition
앞서 나온 것처럼 object 단위로 feature를 생성하기 때문에 N개의 feature field가 있다고 가정할 때 N-1개는 객체, 나머지 하나는 배경에 해당하는 feature field가 됩니다. 배경의 feature 같은 경우에는 화면에 꽉 차야하기 때문에 그에 맞는 scale, translation parameter를 고정한 뒤 사용한다고 합니다.
Composition Operator: composition operator C는 아래와 같이 표현할 수 있습니다.

3.3. Scene Rendering
3D Volume Rendering: NeRF에서 RGB 값에 대한 volume rendering을 하는 것과 동일하게 feature에 대한 volume rendering을 진행합니다. 카메라 포즈에 대한 정보가 주어졌을 때 \({\{x_j\}}^{N_s}_{j=1}\)를 camera ray 상에서 sampling한 지점이라고 가정합니다. 그리고 \({\sigma}_j\)는 density, \(f_j\)는 feature vector라고 가정합니다. Volume rendering operator인 \({\pi}_{vol}\)는 아래와 같이 ray 상의 sample density와 feature를 하나로 합치는 함수입니다.
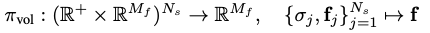
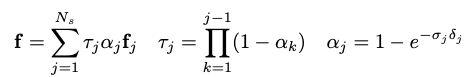
2D Neural Rendering: Neural rendering operator는 위에서 얻은 feature vector를 이미지로 만들어주는 network입니다. 여기서 feature vector의 차원은 실제 이미지보다 크기를 작게하여 연산의 부하를 줄였습니다.
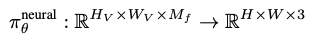
네트워크는 비교적 간단한 CNN block들을 사용하였습니다. 그리고 해당 operator를 통해 얻은 이미지를 가지고 adversarial loss를 적용하여 GAN과 동일하게 이미지를 생성하였습니다.
ETC
이 이후에는 학습 방법 및 다양한 실험을 다루고 있습니다.
배경과 객체가 잘 분리 되어서 생성되고 있는지, 여러 객체들 중 일부를 조정할 때 다른 객체에 영향은 없는지, 잘 조절이 되는지 등을 가지고 실험을 진행하였습니다. 차, 단순 물체, 얼굴 등의 다양한 데이터셋 상에서 실험을 진행하였습니다. 굉장히 잘 되는 편이라서 처음에 나왔을 때 신기하기도 하고, best paper이기도 해서 사람들의 관심을 많이 받았던 기억이 있습니다.

해당 부분에 대해 궁금하신 부분이 있으면 논문을 참고하시면 좋을 것 같습니다.